Unterschied „Brigitte-Test“ zu wissenschaftlich begründeter Eignungsdiagnostik
Eignungsdiagnostik wird nicht nur in der Boulevard-Presse („Bin ich ein Sommertyp?“), sondern auch in der Alltagspsychologie bei der Einschätzung anderer Personen fortlaufend von uns vorgenommen. Wir stellen interindividuelle Unterschiede fest („Michael ist fleißiger als Marco“), wir bewerten intraindividuelle Unterschiede („Genau kann die nicht arbeiten, dafür ist die richtig fleißig“), wir prognostizieren zukünftigen Erfolg („So wie die sich hier anstellt, wird das nichts“) und wir schätzen die Wirkung von Interventionen ab („Wenn ihr mal jemand richtig die Meinung sagt, dann würde die auch mehr Gas geben“). Es stellt sich demnach die Frage nach der Abgrenzung derartiger Alltagspsychologie von Eignungsdiagnostik mit wissenschaftlichem Anspruch.
Alle Urteile grundsätzlich widerlegbar
Eine erste Forderung ist die wissenschaftliche Grundidee der Falsifizierbarkeit, also einer Vorgehensweise, die die diagnostischen Urteile der grundsätzlichen Widerlegbarkeit aussetzt. Die alltagspsychologische Aussage „Ich habe eine gute Menschenkenntnis, ich weiß vorher, ob er mir sympathisch ist“ ist in diesem Sinne nie widerlegbar, weil die betreffende Person gleichzeitig Beurteiler und Maßstab für die Richtigkeit des Urteils ist. Für das AC mit eignungsdiagnostisch wissenschaftlichem Anspruch bedeutet dies, dass die Urteile und die einzelnen Schritte transparent und grundsätzlich angreifbar sein müssen.
Objektivierung und Standardisierung
Im Alltag können wir andere Personen als „Draufgänger“ oder „Schönling“ einordnen. Damit solche Urteile wissenschaftlich werden, bräuchte es objektiv beobachtbare Verhaltensmerkmale. Diese Verhaltensmerkmale müssten so gut sein, dass alle Beobachter anhand dieser Verhaltensmerkmale zur selben Einschätzung kommen. Die Qualität dieser Objektivität lässt sich dann anhand der Korrelation von Beobachtereinschätzung messen.
Verhaltensanker und Bewertungsstufen
In den ACs der 90er Jahre war man noch damit zufrieden, dass die Konstrukte (Dimensionen) mit allgemeinen Verhaltensankern hinterlegt waren. Mittlerweile weiß man, dass die Beobachter eine globale Einschätzung der Leistung in der ganzen Aufgabe vornehmen und dabei, je nach persönlichem Menschenbild, einzelnen Aspekten ein kleines oder großes Gewicht geben (sogenannte implizite Persönlichkeitstheorien). Dies führt im Ergebnis bei gleicher Leistung des Kandidaten im AC zu völlig unterschiedlichen Bewertungen, weswegen allgemeine Verhaltensanker heute nicht mehr ausreichend sind. Zum Standard gehören erstens sogenannte aufgabenspezifische Verhaltensanker und zweitens Bewertungsstufen. Mit den aufgabenspezifischen Verhaltensankern ist gemeint, dass die Erwartung an die Kandidatenleistung vorab anhand des Inhalts der AC-Aufgabe spezifiziert wurde (vgl. Beispiel, Abb.1). Mit den Bewertungsstufen ist gemeint, dass vorab z. B. für eine 5-er-Skala festgelegt wurde, bei welchem Verhalten welche Bewertungsstufe vergeben
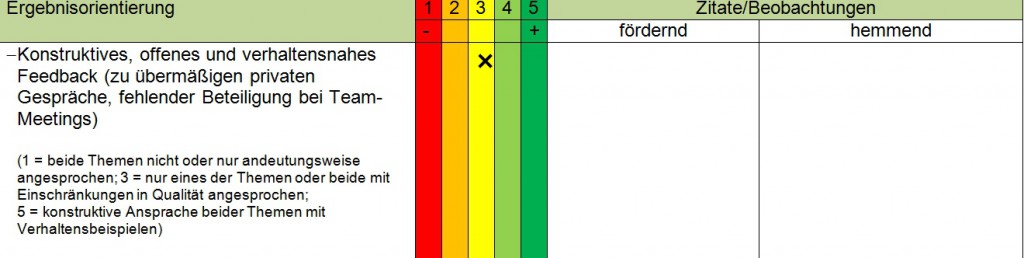
„Gute“ und „schlechte“ Vielfalt von Beobachtereinschätzungen
Ein häufiger Streitpunkt im AC ist es, ob nicht ein zu intensives Beobachtertraining die gewünschte Vielfalt in den Einschätzungen der Beobachter hemmt. Zunächst: Die Vielfalt von verschiedenartigen Blicken auf Kandidaten ist die Grundidee des Assessment Center, um „Kaminkarrieren“ zu verhindern. Gleichzeitig müssen sich diese unterschiedlichen Blickwinkel jedoch im Sinne einer gegenseitigen Kontrolle am gleichen Bewertungsmaßstab ausrichten. Die Vielfalt von Beobachtertypen (z .B. Geschlecht oder Organisationseinheit) ist damit zu begrüßen. Eine Unterschiedlichkeit von Bewertungen bei gleicher Kandidatenleistung schmälert jedoch die Objektivität und auch die Gerechtigkeit.
Ohne Vergleichsnorm keine Ergebnisinterpretation
Die beschriebene Forderung nach Standardisierung würde auch ein Selbsteinschätzungsfragebogen in einer Publikumszeitschrift noch erfüllen. Was dem Laienfragebogen jedoch fehlt, ist eine Vergleichsnorm oder Basisrate, damit erkennbar ist, wie die Einzelperson gegenüber einer Vergleichsnorm abschneidet. Psychologische Konstrukte haben keinen Null-Punkt. Daher braucht es für die Interpretation den Vergleich zu einer Referenzgruppe, so wie die Mutter bei den Schularbeiten wissen wollte, wie denn die anderen Schüler abgeschnitten haben, bevor es Lob oder Tadel gab. Diese Vergleichsnorm besteht aus zwei Informationen: dem Mittelwert und der Standardabweichung der Werte der Vergleichsgruppe. Den Mittelwert braucht es, um zu wissen, ob die betreffende Person ober- oder unterhalb des Durchschnitts der Vergleichsgruppe liegt. Die Standardabweichung braucht es, um einschätzen zu können, ob der Abstand zum Durchschnitt geringfügig oder groß ist.
Eine breite Normierung wird aus ökonomischen Gründen für ein AC, das für lediglich ein paar Dutzend Personen durchgeführt wird, schwer leistbar sein. Dennoch sollte es im Minimum Probeläufe mit Teilnehmern aus der Zielgruppe geben. Damit wird verhindert, dass regelmäßig schwache oder gute Ergebnisse der Teilnehmer ein Artefakt von zu schweren oder zu einfachen Aufgaben sind.
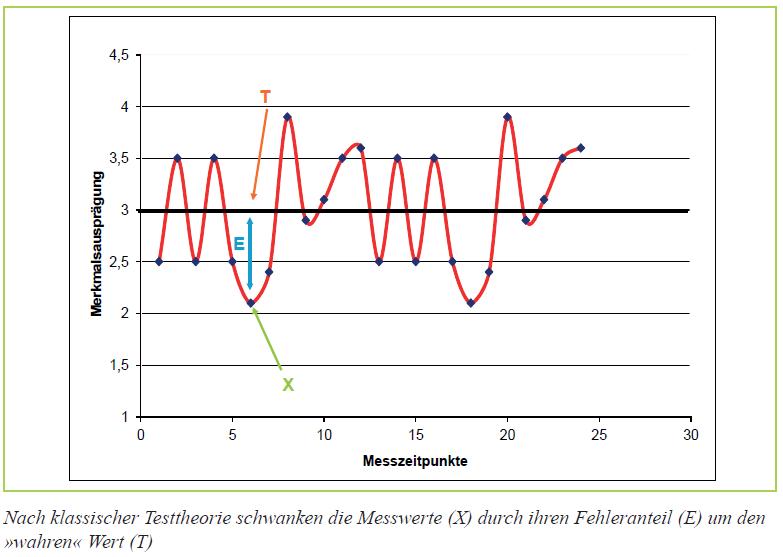
Die Axiome der Testtheorie
Die Klassische Testtheorie (KTT) ist die am weitesten verbreitete psychometrische Testtheorie und stellt die statistische Basis (Cronbach, 1961) für eignungsdiagnostische Messungen und damit auch für das AC dar. Die KTT ist aufgrund ihrer Praktikabilität immer noch die präferierte Testtheorie und Grundlage für die Mehrzahl psychometrischer Testverfahren. Da die KTT bisher jedoch noch wenig Eingang in die AC-Konzeption gefunden hat, lohnt es sich, zunächst diese Basistheorie zu betrachten.
Der Schwerpunkt des Modells der KTT liegt auf der Genauigkeit einer Messung bzw. auf der Größe des jeweiligen Messfehlers. Jede Bewertung im AC enthält – wie jede Antwort in einem Test oder Interview – immer Fehler und Unsicherheiten, z. B. Missverständnisse beim Probanden, Stress-Empfinden oder Beobachtertendenzen. Die KTT versucht zu klären, wie, ausgehend von einem Testwert einer Person, in diesem Kontext die Bewertung auf einer AC-Kompetenz, auf die „wahre“ Ausprägung des zu messenden Persönlichkeitsmerkmals geschlossen werden kann.
Das erste Axiom der KTT besagt, dass sich jeder Testwert (X) additiv zusammensetzt aus einem wahren Merkmalsanteil (T = true), einer stabilen psychologischen Eigenschaft, und einem zufälligen Messfehleranteil (E = error):
X = T + E. Der Anteil von T und E an der Messung X kann unterschiedlich hoch sein.
Beobachtbar im AC sind lediglich die Testwerte (X), z. B. die Dominanz im Auftreten in einer Gruppendiskussion. Der wahre Merkmalsanteil und der Messfehleranteil können jedoch nicht direkt beobachtet werden, sondern werden indirekt ermittelt.
Sicherheit in der Personalauswahl durch viele Messwiederholungen
Das zweite Axiom der KTT bezieht sich auf die Eigenschaften des Messfehlers E. Das Axiom besagt, dass der Messfehler mal positiv, mal negativ ausfällt und in der Summe aller Fehler bei sehr vielen Messwiederholungen Null beträgt.
Beispielhaft kommt in einem Fall eine Person bei einem Test oder AC „besser weg“ als es ihrem wahren Wert entspricht, weil die Beobachter etwa sehr milde waren oder schwierige Fragen ausblieben, dann ist der Messfehler E > 0. In einer anderen Situation ist jedoch der Kandidat nervös oder missversteht die Aufgabenstellung. Dann ist die Bewertung schwächer als der wahre Wert (E < 0). Bei vielen, letztlich unendlich vielen Messungen werden sich diese Fehleranteile zu Null aufheben.
Aus dem zweiten Axiom folgt, dass die Summe der Fehlerwerte einer Person bei unendlich häufiger Messwiederholung unter identischen Bedingungen Null ergeben muss, ebenso wie die Summe der Fehlerwerte bei einmaliger Messung an unendlich vielen Personen.
Wenn bei vielen, in der Theorie unendlichen Messungen der Fehleranteil E der Gleichung X = T + E mit Null anzunehmen ist, so folgt daraus:
Dies besagt, dass der Messfehler verschwindet, wenn entweder ein Test an vielen Individuen angewandt wird oder ein Test mehrfach bei ein und derselben Person angewandt wird. Dies hat für die Eignungsdiagnostik eine bedeutende praktische Konsequenz: Wenn ein Merkmal im AC innerhalb einer AC-Aufgabe oder durch verschiedene AC-Aufgaben mehrfach beobachtet wird, sinkt der Messfehleranteil immer weiter, wogegen die Genauigkeit der durchschnittlichen Bewertung immer weiter steigt. Zwei Interviewfragen zur gleichen Kompetenz beinhalten weniger Fehler als nur eine, drei Fragen weniger als nur zwei. Zwei Interviewer sind besser als einer. Mehr AC-Aufgaben zur Einschätzung ein- und derselben Kompetenz sind besser als nur wenige. Mit jeder weiteren Messwiederholung sinkt der Fehleranteil in der Beurteilung.